Using Multimodal RAG to enhance customer shopping experiences, from precise product recommendations to easy visual searches!
Retail businesses continue to grow with the rapid advancement of technology, changing how consumers interact with brands and products. Today’s shopping behavior is not only about finding products but also about experiencing a personalized, relevant shopping experience that aligns with their needs and preferences. In this context, personalization is key to attracting customers and building lasting loyalty.
Emerging technologies, such as Multimodal RAG (Retrieval-Augmented Generation), have become a revolutionary innovation in retail. This technology combines artificial intelligence (AI) with the ability to access information from various sources. Multimodal RAG allows for a more engaging and enjoyable shopping experience. Not only does it understand consumer needs more accurately, but it also supports more immersive interactions and smarter purchasing decisions.
This article will explore how Multimodal RAG is transforming the retail industry, from creating more accurate product recommendations to delivering a personalized shopping experience.
What is Multimodal RAG?
Multimodal RAG (Retrieval-Augmented Generation) is an AI system that can process and analyze various forms of data or modalities, such as text, images, audio, and video. This method is a state-of-the-art technique for processing and generating maximum information.
This technology enables AI systems to understand the context of various data sources simultaneously, providing more precise, relevant, and user-appropriate answers or solutions. By integrating multiple data modalities, Multimodal RAG encourages AI to better understand the world around us, thus assisting in various aspects of life.
Key Components of Multimodal RAG
The core components of Multimodal RAG involve integrating different types of data, such as text, images, and audio, to generate more accurate and contextual responses in information retrieval and processing systems.
1. Handling Multimodal Input
Multimodal RAG is designed to receive, process, and integrate input from various data formats. For instance, the system can analyze product images, read text descriptions, detect customer voice tones, or understand promotional videos simultaneously, producing comprehensive insights.
2. Retrieval-Augmented Generation Process
- Retrieval (Information Retrieval): The system searches and accesses relevant information from large databases, both internal and external.
- Generation (Information Generation): After retrieving relevant data, the system generates a contextually appropriate response that meets the user’s needs. This process ensures that the results are not only based on static data but also reflect up-to-date information.
3. Integration with AI/ML Systems
Multimodal RAG leverages machine learning (ML) models to continuously adapt to the dynamic preferences of customers. This technology learns customer interaction patterns and changing needs, providing increasingly personalized responses over time.
Relevance in the Retail World
Multimodal RAG holds great potential to revolutionize the retail industry with various applications, such as:
- Customer Service: By understanding different types of input, the system can provide faster and more accurate responses to customer inquiries or complaints, whether through AI Agents or Virtual Assistants.
- Product Recommendations: Multimodal RAG enables systems to provide more precise product recommendations based on customer preferences, purchase history, or visual data such as images of preferred items.
- Enhanced User Engagement: By offering personalized shopping experiences such as voice-guided shopping, interactive product demos, or product descriptions tailored to specific customer needs, Multimodal RAG builds more memorable and engaging interactions.
Informative Shopping with Multimodal RAG Implementation
The main goal of multimodal RAG is to provide a more informative and complete experience by integrating various modalities—not just text, but also images or other visual media. With Qiscus and Multimodal RAG, data is processed quickly, and various types of information are combined, offering users more accurate and visually enriched answers.
Here are some ways multimodal RAG enhances the shopping experience:
1. More Visual Information Delivery
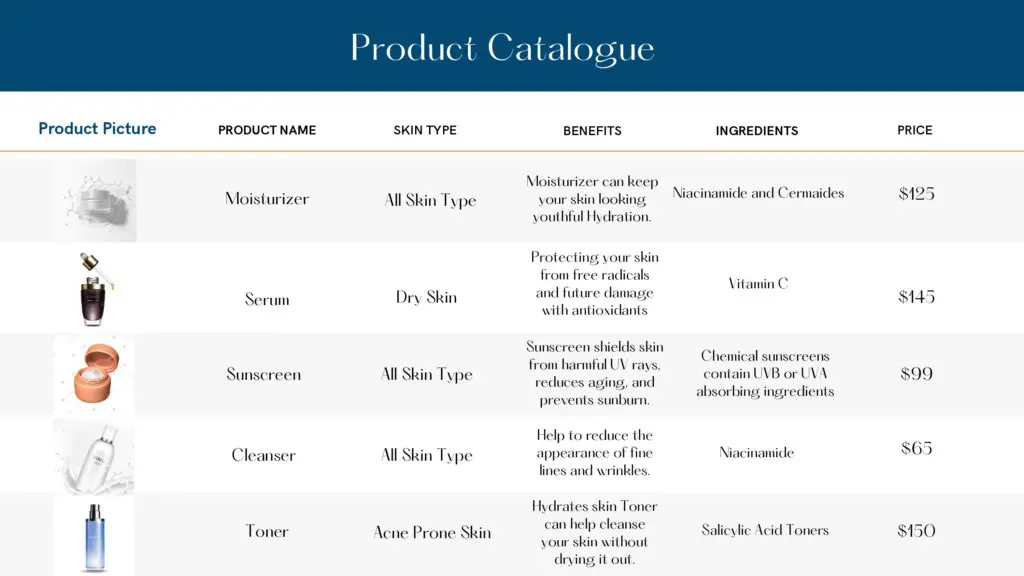
In addition to text, multimodal RAG allows the use of images, diagrams, or other visual media to better depict products.
For instance, if a user is looking for an anti-aging serum, they receive not only the text description of the ingredients and benefits but also an image of the product. This lets users see the product’s appearance, texture, or packaging directly.
2. A More Interactive and Informative Experience
With multimodal RAG, users can receive information in various relevant formats, such as images, videos, or graphics.
For example, if a user asks how to apply foundation for dry skin, the system provides not just text instructions but also a tutorial video or step-by-step images demonstrating the correct application technique.
3. Improved Quality of Recommendations
By combining text and images, product recommendations become clearer and easier to understand.
For example, if a user searches for a moisturizer for oily skin, the system will not only provide the name and description of the product but also show an image of it. This helps users decide if the product suits their needs by allowing them to see the product’s packaging or texture.
Use Case: Multimodal RAG in Visual Product Search
Visual product search using Multimodal RAG technology introduces a new way for customers to find products more easily and effectively. This technology combines image analysis, text comprehension, and context-based searching, enabling faster and more relevant shopping experiences.
Multimodal RAG Flow Process
The flow of Multimodal RAG involves retrieving data from various sources, integrating multimodal information, and processing it generatively to produce more accurate and contextual responses.
- Multimodal Input: Users provide input in the form of product images (e.g., hiking boots) and text descriptions (e.g., “waterproof brown hiking boots”). This system can understand user needs through a combination of visual and linguistic data.
- Search Process:
- Visual Feature Extraction: The AI model analyzes the image to detect elements such as color, texture, shape, and unique patterns.
- Text Comprehension: The text description is processed to extract keywords or key phrases that describe specific product features.
- Modality Combination: The system combines visual and text analysis to create a richer search context, improving product matching accuracy.
- Information Augmentation: Additional information, such as product specifications, user reviews, pricing, and related recommendations, is pulled from the knowledge base.
Multimodal Output
The system generates a list of products that match the user’s needs, complete with:
- Product images
- Pricing and availability
- Detailed specifications
- Customer reviews
- Recommendations for similar or complementary products
Case Examples
- Visual Search Mode
Scenario: A user wants to find a bag with a similar design to one they saw on social media. They upload an image of the bag and add a text description, such as “black leather bag with chain straps and minimalist design.”
Output: The system shows similar products available in the online store, with detailed pricing, user reviews, and product specifications. - Complementary Accessory Search
Scenario: A user uploads an image of formal clothing and asks, “What accessories would go well with this?”
Output: The system suggests items like elegant watches, formal shoes, or simple jewelry that matches the outfit style.
Advantages of Technology in Visual Product Search
Visual search technology makes it easier for users to find products more quickly and accurately using just images or simple descriptions, while also providing personalized recommendations based on their preferences.
- Intuitive: Users don’t need to know the product name; a simple image or description is enough to begin the search.
- Efficient: The combination of visual and text analysis delivers clearer matches in a short time.
- Personalized: Recommendations are tailored to customers’ specific needs, enhancing satisfaction and loyalty.
Conclusion
Multimodal RAG is transforming the shopping experience by integrating text, images, audio, and other data to create more personalized and efficient solutions. This technology enables features like specific product recommendations, visual search, and virtual assistants that enhance convenience and strengthen emotional connections with customers.
With trends like predictive analytics and voice-based shopping, the retail industry has an opportunity to meet customer desires and provide a more memorable shopping experience. Multimodal RAG is not just a technological tool but a symbol of the retail industry’s shift toward a more engaging and enjoyable experience.
Make your customers’ shopping experience more enjoyable with Qiscus. Contact Qiscus here for an explanation and demo from us!