
Dalam beberapa tahun terakhir, kemajuan model bahasa besar (LLM) seperti GPT, Claude, dan Gemini telah merevolusi cara kita membangun dan menggunakan sistem AI. Namun, seiring berkembangnya kemampuan model-model ini, muncul kebutuhan yang semakin mendesak untuk mengevaluasi performanya secara efektif, objektif, dan berskala besar.
Tradisionalnya, evaluasi AI banyak mengandalkan penilaian manusia—yang disebut juga sebagai human evaluation. Para evaluator manusia diminta untuk membandingkan atau menilai jawaban dari AI berdasarkan kriteria tertentu seperti akurasi, relevansi, dan gaya bahasa. Meskipun pendekatan ini dianggap sebagai “gold standard”, evaluasi manual memiliki keterbatasan dari segi biaya, waktu, dan konsistensi.
Untuk menjawab tantangan tersebut, muncullah paradigma baru: LLM-as-a-Judge. Dalam pendekatan ini, AI tidak hanya menjadi objek evaluasi, tetapi juga aktor evaluatif. Model LLM digunakan sebagai evaluator otomatis untuk menilai performa sistem AI lainnya, dengan efisiensi dan skala yang jauh melampaui kemampuan manusia.
Namun, apakah pendekatan ini bisa diandalkan sepenuhnya? Bagaimana ia dibandingkan dengan evaluasi oleh manusia? Apa saja jenis pendekatan dan bias yang perlu diwaspadai? Mari kita telaah lebih lanjut dalam bagian berikut ini.
Apa yang Dimaksud dengan LLM-as-a-Judge?
LLM-as-a-Judge adalah teknik evaluasi inovatif yang memanfaatkan kecerdasan model bahasa besar (LLM) untuk menilai berbagai aspek dalam sistem AI. Dengan pendekatan strategis, metode ini memungkinkan LLM untuk menganalisis kualitas output, baik dari model lain maupun dari anotasi manusia.
Pendekatan ini sangat berguna ketika metode evaluasi tradisional—seperti perbandingan statistik dengan data ground truth—tidak cukup. Fleksibilitas LLM-as-a-Judge terletak pada kemampuannya untuk menyesuaikan diri dengan berbagai tugas evaluasi, dengan mengandalkan well-designed prompts untuk mengoptimalkan penalaran model LLM.
Pendekatan dalam LLM-as-a-Judge
Dalam evaluasi ini, LLM bertugas memberikan skor dan penalaran berdasarkan kriteria yang telah ditentukan. Berikut adalah beberapa pendekatan utamanya.
1. Single Output Scoring (without reference)
LLM memberikan skor berdasarkan kriteria yang telah ditentukan sebelumnya, tanpa menggunakan referensi tambahan.
- Skor diberikan dalam skala diskrit dengan nilai yang terbatas.
- Setiap nilai memiliki definisi yang jelas untuk memastikan konsistensi dalam penilaian.
- LLM hanya mengandalkan output dan kriteria evaluasi yang ada di dalam prompt.
- Metode ini cocok untuk evaluasi sederhana, di mana kualitas output dapat dinilai secara independen tanpa perlu perbandingan atau konteks tambahan.
2. Single Output Scoring (with reference)
Pendekatan ini merupakan pengembangan dari metode sebelumnya dengan menambahkan referensi sebagai konteks tambahan untuk membantu LLM dalam mengevaluasi output.
- Prompt mencakup referensi, seperti langkah-langkah penalaran, jawaban yang diharapkan, atau detail relevan lainnya.
- Referensi ini membantu LLM menilai output dengan lebih akurat dan terinformasi.
- Metode ini sangat berguna untuk evaluasi yang lebih kompleks, karena memberikan konteks tambahan yang memungkinkan analisis lebih mendalam dan akurat.
3. Pairwise Comparison
Pendekatan Pairwise Comparison melibatkan perbandingan langsung antara dua output untuk menentukan mana yang lebih baik.
- Judge LLM diberikan dua input dan diminta memilih yang lebih unggul berdasarkan kriteria yang ditetapkan.
- Pendekatan ini membantu mengatasi beberapa tantangan dalam penilaian absolut, karena LLM hanya perlu membuat penilaian komparatif.
Pendekatan Penilaian dengan LLM-as-a-Judge
Metode ini sangat efektif untuk evaluasi relatif, terutama dalam skenario di mana kualitas output sulit diukur secara mutlak. Meskipun scoring schemas memberikan penilaian kuantitatif yang berharga terhadap output LLM, menambahkan explanations dari evaluating LLM dapat memperkaya proses evaluasi secara signifikan.
Dengan meminta LLM untuk mengartikulasikan alasannya dalam memberikan penilaian, kita dapat memperoleh wawasan yang lebih dalam tentang proses pengambilan keputusannya. Explanations ini menawarkan berbagai manfaat:
- Meta-evaluation: Memungkinkan kita menilai keandalan dan konsistensi model LLM-as-a-Judge itu sendiri.
- Training data: Dapat digunakan sebagai anotasi berkualitas tinggi untuk fine-tuning model lain.
- Explainability: Memberikan justifikasi yang transparan terhadap skor yang diberikan, meningkatkan kepercayaan dan pemahaman dalam proses evaluasi.
- Diagnostic tool: Membantu mengidentifikasi kekuatan atau kelemahan spesifik dalam output yang dievaluasi, sehingga dapat digunakan untuk perbaikan yang lebih terarah.
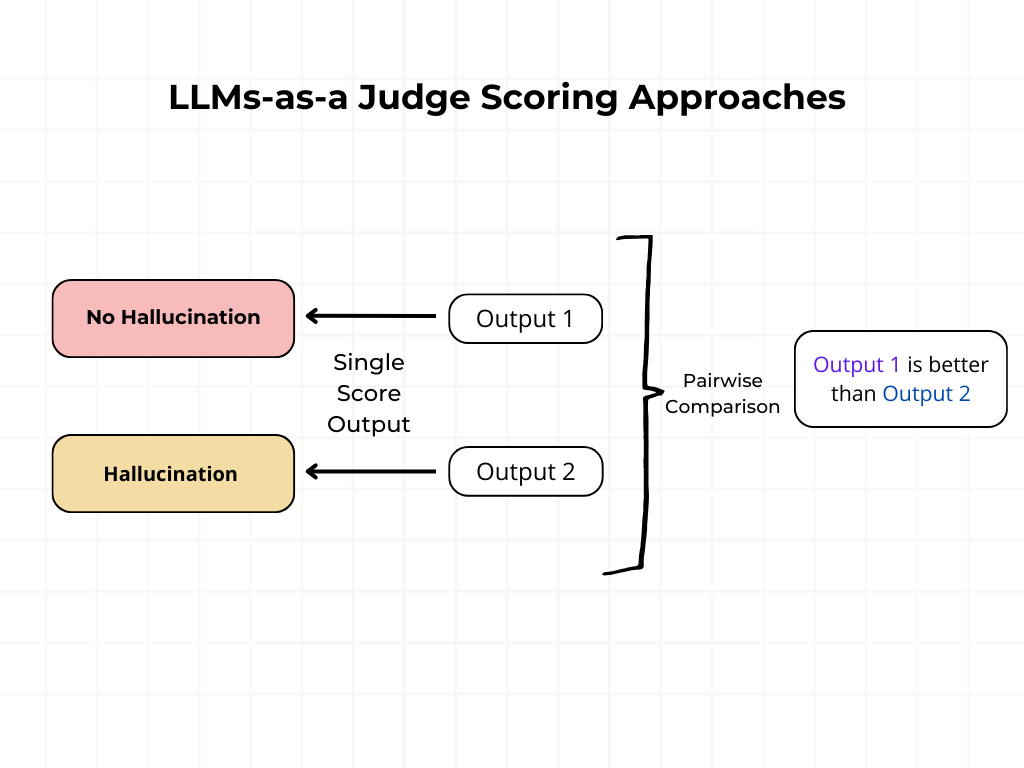
Tidak ada satu metode evaluasi yang secara universal lebih baik dari yang lain. Sebagai contoh, pairwise comparisons sangat baik dalam menentukan kualitas relatif antara output, tetapi mungkin tidak memberikan metrik kinerja absolut seperti metode single output scoring.
Namun, hasil dari metode single output scoring bisa menjadi kurang dapat diandalkan, karena skor absolut cenderung lebih bervariasi dibandingkan dengan hasil pairwise, terutama jika LLM judge mengalami pembaruan atau diganti. Hal ini telah dibahas dalam Judging LLM-as-a-Judge with MT-Bench and AI Agents Arena.
Metode pairwise comparison juga memiliki keterbatasan dalam scalability, karena jumlah perbandingan yang diperlukan bertambah secara eksponensial seiring bertambahnya jumlah samples/models. Namun, dalam beberapa kasus, hanya menggunakan sebagian perbandingan sudah cukup, dan kita tetap dapat mengaitkannya dengan skor global, seperti yang dilakukan dalam metode EvaluLLM berdasarkan rekomendasi dari Human-Centered Design Recommendations for LLM-as-a-Judge.
Seiring dengan semakin kuatnya model bahasa yang mendukung LLM-as-a-Judge, pendekatan ini sering kali muncul sebagai metode evaluasi yang paling efisien. Beberapa keunggulan utamanya dibandingkan evaluasi manusia meliputi:
- Scalability: LLM dapat memproses sejumlah besar data dengan cepat, menjadikannya ideal untuk evaluasi dalam skala besar.
- Cost-Effectiveness: Mengurangi ketergantungan pada tenaga kerja manusia, sehingga secara signifikan menekan biaya.
- Flexibility: LLM dapat fine-tuned atau prompt-engineered untuk tugas tertentu, meningkatkan relevansi dan mengurangi bias.
- Complex Understanding: Mampu mengevaluasi teks yang kompleks dalam berbagai format, menghasilkan penilaian yang lebih mendalam.
- Bias Reduction: Dengan penyempurnaan sistematis terhadap prompts dan penggunaan few-shot samples, LLM dapat membantu mengurangi beberapa bias yang mungkin secara tidak sadar diperkenalkan oleh evaluator manusia.
Tantangan dalam Human Evaluation
Selama ini, human judges dianggap sebagai gold standard dalam mengevaluasi output yang dihasilkan oleh AI. Saat kita mencari cara yang lebih efektif dan adil, penting untuk memahami kelemahan pendekatan ini.
Sebuah studi terbaru berjudul “Human Feedback is Not Gold Standard” menyoroti adanya bias dalam penggunaan human preference scores untuk melatih dan mengevaluasi model bahasa besar (LLM). Penelitian ini menekankan perlunya metode evaluasi yang lebih sistematis, mendalam, dan objektif agar AI dapat dinilai dengan lebih akurat.
1. Faktor Pengganggu (Impact of Confounding Factors)
Studi ini meneliti bagaimana dua confounding factors—assertiveness dan complexity—mempengaruhi evaluasi manusia. Dengan menggunakan model AI yang telah disesuaikan instruksinya, para peneliti mengamati bahwa output yang terdengar lebih pasti dan meyakinkan (assertive) sering kali dianggap lebih akurat, meskipun isinya belum tentu benar.
Hasil ini menunjukkan bahwa manusia secara tidak sadar dapat terpengaruh oleh cara informasi disampaikan, bukan oleh kebenaran faktualnya. Artinya, semakin percaya diri sebuah jawaban terdengar, semakin besar kemungkinan orang mempercayainya—terlepas dari apakah informasi tersebut benar atau tidak.
2. Biar Skor Preferensi (Bias in Preference Scores)
Para authors berpendapat bahwa preference scores, yang digunakan untuk menilai kualitas output LLM, bersifat subjektif secara inheren. Dengan kata lain, preferensi seseorang tidak selalu mewakili pandangan universal dan dapat memicu bias yang tidak disengaja dalam evaluasi. Akibatnya, bias ini dapat mempengaruhi hasil penilaian, berpotensi menciptakan kesimpulan yang keliru tentang kinerja model AI.
3. Gagal Mendeteksi Kesalahan (Low Coverage of Factual Errors)
Salah satu temuan yang mengkhawatirkan adalah bahwa model dapat menerima penilaian positif meskipun menghasilkan informasi yang keliru, selama gaya atau cara penyampaiannya disukai oleh evaluator manusia. Ketidaksesuaian antara kualitas yang dirasakan dan akurasi faktual ini dapat menjadi risiko besar bagi keandalan sistem AI.
4. Umpan Balik Merugikan (Harmful Feedback Loops)
Karena bias manusia terhadap respons yang lebih assertive, ada bukti awal bahwa pelatihan model menggunakan human feedback dapat secara tidak proporsional meningkatkan tingkat assertiveness dalam output AI. Akibatnya, model bisa menjadi terlalu percaya diri, bahkan ketika jawaban yang diberikan tidak sepenuhnya akurat. Hal ini berisiko menyesatkan pengguna dan pada akhirnya dapat mengurangi kepercayaan terhadap sistem AI.
5. Efisiensi Sumber Daya (Resource Intensiveness)
Melakukan evaluasi manusia dalam skala enterprise memerlukan biaya tinggi dan waktu yang lama. Proses ini membutuhkan:
- Koordinasi dengan annotators
- Pengembangan custom web interfaces
- Pembuatan instruksi anotasi yang rinci
- Analisis data yang mendalam
- Manajemen pekerja lepas (crowd workers) yang cermat
Karena membutuhkan banyak sumber daya, proses ini sering menjadi hambatan utama dalam eksperimen dan pengembangan sistem AI, yang pada akhirnya dapat memperlambat inovasi di bidang ini.
Tantangan dalam Evaluasi Berbasis LLM
Evaluasi berbasis LLM juga bisa mengalami bias, seperti halnya anotasi manusia, karena model ini dilatih dengan data yang dibuat oleh manusia. Namun, tantangan ini dapat diminimalkan dengan strategi yang tepat.
1. Nepotism Bias
LLM evaluators secara inheren lebih menyukai teks yang mereka hasilkan sendiri. Misalnya, jika kita meminta GPT-4 untuk menilai dua ringkasan artikel tentang “Dampak perubahan iklim,” di mana satu ringkasan dibuat oleh GPT-4 dan satu lagi oleh Claude Sonnet, GPT-4 mungkin akan memberikan skor lebih tinggi pada ringkasan yang dibuatnya sendiri. Padahal, kedua ringkasan tersebut sama akurat dan informatifnya. Ini menunjukkan bahwa model cenderung lebih menyukai gaya penulisan dan struktur yang sudah familiar bagi mereka.
2. Authority Bias
Bias ini terjadi ketika sebuah pernyataan dianggap lebih kredibel hanya karena berasal dari sumber yang dianggap otoritatif, tanpa mempertimbangkan bukti yang diberikan.
Misalnya, jika LLM diminta mengevaluasi dua ulasan tentang efektivitas suatu metode pembelajaran (quantum mechanics) satu dari seorang profesor senior dan satu lagi dari seorang guru muda yang aktif mengajar di lapangan—model mungkin lebih cenderung mendukung ulasan profesor, meskipun ulasan dari guru muda lebih relevan dan didukung oleh data terbaru.
3. Beauty Bias
Penelitian “Humans or LLMs as the Judge? A Study on Judgement Biases” menunjukkan bahwa model bahasa besar (LLM) cenderung lebih menyukai teks yang secara estetika menarik, meskipun informasi yang disampaikan tidak lebih akurat atau komprehensif. Contohnya:
- Ulasan 1: “Laptop ini menghadirkan performa tinggi dengan prosesor terbaru, RAM 16GB, dan daya tahan baterai hingga 12 jam, menjadikannya pilihan ideal untuk profesional yang membutuhkan keandalan sepanjang hari.”
- Ulasan 2: “Laptop ini luar biasa! Desainnya elegan, kinerjanya cepat, dan baterainya awet. Sempurna untuk siapa saja yang menginginkan perangkat andal.”
Meskipun Ulasan 1 lebih informatif dan mencantumkan detail teknis yang relevan, LLM mungkin lebih cenderung memberikan skor lebih tinggi pada Ulasan 2 karena bahasanya lebih alami dan terasa lebih menarik.
4. Verbosity Bias
Model bahasa besar (LLM) dapat menunjukkan bias terhadap panjang teks, di mana mereka cenderung lebih menyukai respons yang lebih panjang dan rinci, meskipun informasi tambahan tersebut mungkin tidak relevan atau bahkan mengurangi kualitas keseluruhan.
Penelitian menunjukkan bahwa LLM cenderung memberikan preferensi pada respons yang lebih panjang, yang dapat mempengaruhi keandalan evaluasi yang dilakukan oleh model tersebut. Contohnya:
Pertanyaan: “Bagaimana cara kerja mesin pencari?”
- Jawaban 1: Mesin pencari mengindeks halaman web dan menampilkan hasil berdasarkan relevansi dengan kata kunci pencarian.”
- Jawaban 2: Mesin pencari, seperti Google, menggunakan proses yang kompleks untuk membantu pengguna menemukan informasi di internet. Pertama, mereka mengirim ‘crawler’ atau ‘spider’ untuk menjelajahi web dan mengumpulkan data dari berbagai situs.
Data ini kemudian diindeks dan disimpan dalam database besar. Ketika pengguna memasukkan kata kunci, mesin pencari menganalisis indeks ini untuk menemukan hasil yang paling relevan. Faktor-faktor seperti kualitas konten, jumlah tautan masuk, dan kepuasan pengguna sebelumnya juga dipertimbangkan dalam menentukan peringkat hasil pencarian.
Meskipun Jawaban 2 lebih panjang dan rinci, informasi tambahan tersebut mungkin tidak sepenuhnya relevan atau diperlukan untuk menjawab pertanyaan dengan efektif. Namun, LLM mungkin lebih cenderung menilai Jawaban 2 sebagai lebih berkualitas karena panjang dan detailnya, meskipun Jawaban 1 sudah memberikan jawaban yang akurat dan ringkas.
5. Positional Bias
Model bahasa besar (LLM) dapat menunjukkan Positional Bias, yaitu kecenderungan untuk memberikan bobot lebih pada informasi yang terletak di awal atau akhir sebuah dokumen, sementara mengabaikan detail penting di bagian tengah. Bias ini dapat mempengaruhi kemampuan LLM dalam memahami dan meringkas teks secara akurat.
6. Attention Bias
LLMs terkadang dapat melewatkan informasi kontekstual yang terdapat di tengah teks yang panjang. Bias ini menunjukkan bahwa model cenderung lebih fokus pada bagian awal dan akhir, yang dapat menyebabkan pemahaman atau interpretasi yang tidak lengkap.
Misalnya, dalam mengevaluasi dokumen hukum yang panjang, LLM mungkin dapat mengingat dengan baik pernyataan pembuka dan argumen penutup tetapi kesulitan mengintegrasikan nuansa penting yang dibahas di bagian tengah dokumen, sehingga menghasilkan penilaian yang kurang akurat.
7. Chain-of-Thought Reasoning
Chain-of-Thought (CoT) prompting adalah cara sederhana namun efektif untuk membantu model bahasa (LLM) memberikan jawaban yang lebih akurat. Teknik ini mengarahkan model untuk berpikir secara bertahap sebelum memberikan jawaban akhir, sehingga hasilnya lebih terstruktur dan mendalam.
Dengan CoT prompting, model dapat memproses informasi secara lebih sistematis, menghasilkan jawaban yang lebih akurat.
How to Think About GenAI Evaluation
Evaluasi AI generatif perlu disesuaikan dengan konteks penggunaannya. Kerangka ini memberikan panduan terstruktur untuk menilai model AI, mulai dari menentukan skenario evaluasi hingga menganalisis hasil secara objektif dan subjektif.
Dengan pendekatan yang sistematis dan menyeluruh, kita dapat memahami bagaimana AI bekerja, mengukur kelebihan dan kekurangannya, serta memastikan bahwa model yang digunakan benar-benar efektif dan sesuai dengan kebutuhan.

Evaluasi RAG
Pada bagian ini menjelaskan cara mengevaluasi RAG (Retrieval-Augmented Generation) dengan membangun dataset evaluasi sintetis dan menggunakan LLM sebagai penilai untuk mengukur akurasi sistem.
Sistem RAG cukup kompleks, dan ada banyak cara untuk meningkatkannya. Namun, tanpa evaluasi yang baik, perubahan apa pun bisa menjadi tidak efektif. Oleh karena itu, benchmarking sistem RAG sangat penting.
Langkah-langkah Evaluasi RAG
Untuk menilai performa dan efektivitas sistem Retrieval-Augmented Generation (RAG), evaluasi perlu dilakukan secara sistematis. Proses ini mempertimbangkan aspek retrieval (pencarian), generation (pembuatan respons), dan integrasi antar keduanya. Berikut adalah langkah-langkah umum yang dapat digunakan dalam proses evaluasi RAG.
1. Membangun Dataset Evaluasi Sintetis
Langkah pertama adalah membuat dataset pertanyaan-jawaban (QA) yang relevan dan terstruktur. Caranya, Anda bisa menggunakan LLM untuk membuat pertanyaan-pertanyaan ini secara otomatis. Setelah itu, pertanyaan-pertanyaan tersebut disaring menggunakan LLM agent lain yang bertugas sebagai “agen kritik” untuk memastikan kualitasnya. Proses ini menjamin dataset evaluasi Anda berkualitas tinggi dan sesuai dengan skenario yang diinginkan.
2. Menyiapkan Agen Evaluasi
Agen kritik ini digunakan untuk menilai setiap pertanyaan dalam dataset berdasarkan tiga kriteria utama:
- Groundedness: Apakah pertanyaan dapat dijawab dengan konteks yang tersedia dari sumber data?
- Relevance: Seberapa relevan pertanyaan ini bagi pengguna akhir?
- Stand-alone: Apakah pertanyaan dapat dipahami tanpa konteks tambahan? Pertanyaan yang mendapat skor rendah dalam kriteria ini akan dihapus dari dataset. Ini memastikan hanya pertanyaan dengan skor tinggi yang digunakan dalam evaluasi akhir, sehingga hasil penilaian lebih akurat dan bermakna.
3. Menggunakan Dataset Evaluasi
Setelah dataset disaring dan hanya pertanyaan berkualitas tinggi yang tersisa, sistem RAG Anda dapat diuji performanya secara objektif. Dengan menggunakan dataset evaluasi ini, Anda bisa melihat seberapa baik sistem RAG Anda dalam memberikan jawaban yang akurat dan relevan.
Hasilnya dapat digunakan untuk mengidentifikasi kelemahan dan melakukan peningkatan yang benar-benar berdampak pada performa sistem Anda. Pendekatan ini memungkinkan Anda untuk mengukur efektivitas sistem RAG secara terstruktur dan terukur.
Kesimpulan
LLM-as-a-Judge menawarkan solusi yang lebih cepat dan hemat biaya dibandingkan evaluasi manusia, tetapi tetap memiliki beberapa tantangan. Dengan memahami bias yang mungkin muncul dan mengoptimalkan prompt untuk evaluasi yang lebih adil, LLM dapat menjadi alat yang sangat efektif dalam menilai kinerja AI. Di masa depan, kombinasi antara evaluasi AI dan manusia mungkin menjadi pendekat


