
Saat ini, volume percakapan antara pelanggan dan perusahaan terus meningkat secara eksponensial. Baik melalui live chat, WhatsApp, email, hingga media sosial, setiap interaksi menyimpan data mentah yang berharga. Namun, data tersebut sering kali tidak terstruktur dan sulit dimanfaatkan secara langsung.
Di sinilah unsupervised learning berperan. Dengan pendekatan machine learning yang tidak membutuhkan label data, perusahaan dapat mengekstraksi pola, tren, dan insight dari ribuan hingga jutaan percakapan pelanggan secara otomatis. Hasilnya adalah real-time customer intelligence yang dapat meningkatkan pengalaman pelanggan sekaligus efisiensi tim support.
Pada sesi AI Insight, Muhammad Fadhil Amri, Backend Engineer Qiscus, membagikan bagaimana perusahaan dapat mengoptimalkan unsupervised learning untuk mengubah percakapan mentah menjadi wawasan yang actionable.
Agar lebih mudah dipahami, saksikan video lengkap di atas dan baca penjelasan selengkapnya di artikel berikut.
Apa itu Unsupervised Learning?
Unsupervised learning adalah salah satu cabang dari machine learning yang berfokus pada analisis data tanpa label. Tidak seperti supervised learning yang membutuhkan data dengan kategori atau jawaban yang sudah ditentukan sebelumnya, unsupervised learning bekerja langsung pada data mentah dan berusaha menemukan pola serta struktur tersembunyi di dalamnya.
Pendekatan ini sangat berguna ketika kita memiliki volume data yang besar, tetapi tidak memiliki waktu atau sumber daya untuk melakukan pelabelan manual.
1. Menganalisis Data Tanpa Label (Analyzes Unlabeled Data)
Dalam banyak kasus, data yang dimiliki perusahaan berupa teks bebas, angka, log, atau metadata yang tidak terstruktur. Unsupervised learning mampu menganalisis kumpulan data ini dan mengelompokkannya berdasarkan kemiripan atau karakteristik tertentu tanpa arahan khusus dari manusia.
Misalnya, ribuan percakapan pelanggan dapat dikelompokkan menjadi topik-topik utama seperti keluhan teknis, pertanyaan harga, atau permintaan fitur baru—semuanya dilakukan secara otomatis tanpa label awal.
2. Menemukan Struktur Tersembunyi (Discovers Hidden Structures)
Algoritma seperti clustering dan dimensionality reduction dapat mengidentifikasi pola, kelompok, atau bahkan anomali dalam data.
Dalam konteks customer support, hal ini memungkinkan perusahaan untuk mendeteksi tren masalah tertentu, menemukan kelompok pelanggan dengan perilaku serupa, atau mengenali anomali seperti lonjakan keluhan yang bisa menandakan adanya gangguan layanan.
3. Belajar Secara Mandiri (Learns Autonomously)
Unsupervised learning memungkinkan sistem AI untuk belajar dan beradaptasi langsung dari data mentah. Artinya, semakin banyak data baru yang masuk, sistem dapat terus memperbaiki pemahamannya terhadap pola tanpa perlu intervensi manual atau pelabelan ulang.
Hal ini mengurangi ketergantungan pada sumber daya manusia dan mempercepat waktu analisis sehingga perusahaan bisa mendapatkan insight secara real-time.
Mengapa Unsupervised Learning Penting?
Dalam konteks ini, unsupervised learning hadir sebagai solusi yang memungkinkan perusahaan menggali insight tersembunyi dari data dalam skala besar.
1. Ledakan Data Tanpa Label (Unlabeled Data Overload)
Ketika data tanpa label ini menumpuk, proses analisis manual menjadi mustahil dilakukan. Tanpa metode cerdas untuk mengelolanya, perusahaan berisiko kehilangan peluang penting untuk memahami kebutuhan dan masalah pelanggan.
2. Skalabilitas dalam Menghasilkan Insight (Scaling Insights)
Keunggulan utama unsupervised learning adalah kemampuannya mengekstraksi wawasan bernilai secara otomatis. Teknologi ini memungkinkan analisis dilakukan dalam skala besar tanpa campur tangan manusia, sehingga insight yang tadinya butuh waktu berminggu-minggu bisa didapatkan dalam hitungan menit.
Bagi tim customer support, hal ini berarti mereka bisa lebih cepat memahami tren masalah, mendeteksi isu yang muncul, dan mengambil keputusan strategis untuk meningkatkan layanan.
Implementasi Unsupervised Learning dalam Customer Support
Unsupervised learning menawarkan berbagai solusi yang mampu mengubah data percakapan mentah menjadi wawasan yang dapat ditindaklanjuti. Tiga aplikasi utamanya yang paling relevan untuk customer support adalah sebagai berikut.
1. Customer Segmentation
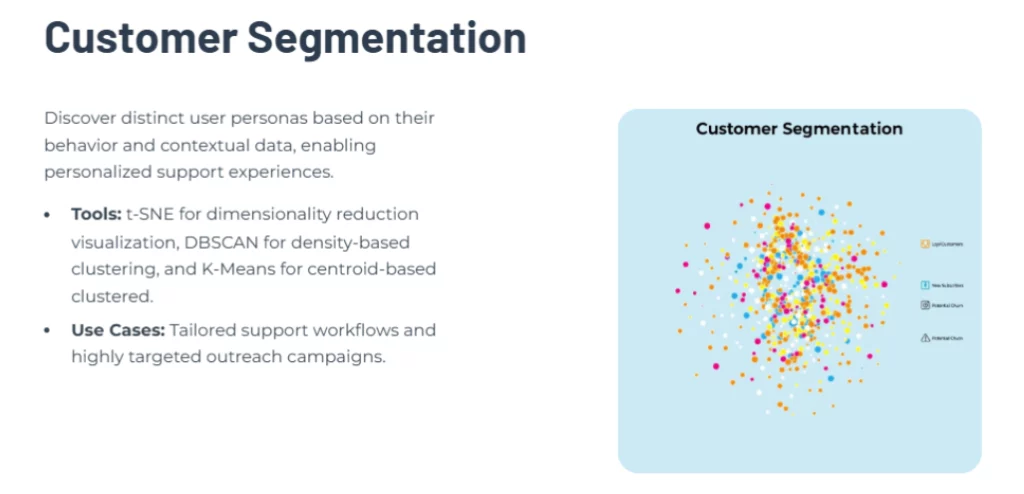
Dengan unsupervised learning, perusahaan dapat memahami pelanggan berdasarkan perilaku dan pola interaksinya. Misalnya, pelanggan yang sering menghubungi tim support untuk masalah teknis dapat dipisahkan dari pelanggan yang lebih banyak bertanya tentang harga atau promosi.
Segmentasi pelanggan dilakukan dengan menggunakan algoritma clustering yang menganalisis pola interaksi. Beberapa tools yang umum digunakan antara lain:
- t-SNE (t-distributed Stochastic Neighbor Embedding) untuk menyederhanakan data berdimensi tinggi sehingga mudah divisualisasikan.’
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise) untuk menemukan cluster berdasarkan kepadatan data, cocok untuk dataset yang tidak berbentuk bulat sempurna.
- K-Means untuk mengelompokkan pelanggan ke dalam cluster berdasarkan kesamaan karakteristik tertentu.
Segmentasi ini membantu tim support dan marketing untuk memberikan pendekatan yang lebih personal, seperti mengutamakan layanan cepat untuk pelanggan bernilai tinggi atau menyiapkan materi edukasi bagi pelanggan baru.
Teknik segmentasi pelanggan dengan unsupervised learning dapat diterapkan dalam berbagai skenario praktis yang langsung berdampak pada efisiensi tim support maupun strategi bisnis perusahaan. Beberapa contoh penerapannya adalah sebagai berikut:
- Tailored Support Workflows: Dengan segmentasi, perusahaan bisa menyiapkan alur dukungan berbeda untuk setiap tipe pelanggan. Misalnya, pelanggan baru mendapat panduan onboarding, sementara pelanggan lama mendapat prioritas dukungan teknis.
- Targeted Outreach Campaigns: Segmentasi juga membantu tim marketing dalam menjalankan kampanye yang lebih tepat sasaran. Pelanggan yang sering memberikan feedback positif bisa dilibatkan dalam program loyalty, sedangkan pelanggan dengan keluhan berulang bisa difokuskan pada program retensi.
2. Topic Clustering

Percakapan pelanggan biasanya beragam dan tidak terstruktur. Melalui teknik topic clustering, sistem dapat menemukan pola percakapan yang serupa dan mengelompokkannya ke dalam topik tertentu.
Topic clustering memanfaatkan representasi vektor dari teks (embedding) untuk mengukur kemiripan antar percakapan. Percakapan dengan pola kata dan konteks serupa akan dikelompokkan ke dalam satu cluster. Beberapa tools yang sering digunakan adalah:
- BERTopic, sebuah metode berbasis transformer yang mampu mengidentifikasi dan melabeli topik dengan lebih akurat.
- K-Means, algoritma clustering klasik yang mengelompokkan data ke dalam sejumlah cluster tertentu berdasarkan kedekatan vektor.
- Advanced Embedding Techniques, seperti sentence transformers yang menghasilkan representasi teks lebih bermakna untuk analisis semantik.
Contohnya, ratusan chat terkait “kendala login” bisa dikelompokkan menjadi satu cluster, sementara “pertanyaan tentang metode pembayaran” menjadi cluster lain. Dengan cara ini, perusahaan dapat memantau tren masalah yang sedang meningkat dan segera menyiapkan solusi terarah.
Penerapan teknik topic clustering dalam customer support dapat memberikan dampak nyata terhadap efisiensi operasional maupun pengalaman pelanggan. Berikut adalah beberapa contoh bagaimana teknologi ini digunakan dalam praktik:
- Automated Issue Routing: Percakapan pelanggan dapat langsung diarahkan ke tim yang tepat (misalnya masalah billing ke tim finance, kendala login ke tim teknis) tanpa perlu penyortiran manual.
- Proactive Trend Discovery: Perusahaan dapat menemukan tren masalah baru sebelum menjadi isu besar. Contohnya, jika banyak pelanggan tiba-tiba mengeluhkan fitur tertentu, sistem akan mengidentifikasinya sebagai topik baru.
- Intelligent Auto-Labeling: Dengan clustering, sistem dapat menambahkan label otomatis pada tiket support, sehingga mempercepat proses resolusi dan meningkatkan efisiensi tim.
3. Anomaly Detection

Tidak semua percakapan mengikuti pola umum. Kadang muncul interaksi yang berbeda atau menyimpang dari biasanya, misalnya lonjakan keluhan dalam waktu singkat atau adanya isu yang belum pernah muncul sebelumnya.
Anomaly detection bekerja dengan mempelajari pola umum dari data, kemudian menandai data yang berbeda secara signifikan sebagai anomali. Beberapa metode yang sering digunakan antara lain:
- Isolation Forest: efektif untuk mengisolasi data outlier dengan membangun pohon acak.
- One-Class SVM (Support Vector Machine): cocok untuk mendeteksi novelty atau kejadian baru yang belum pernah ada sebelumnya.
- K-Means: terkadang digunakan untuk mendeteksi anomali berbasis cluster, meskipun kurang direkomendasikan untuk kasus kritis.
Melalui anomaly detection, perusahaan bisa mendeteksi masalah sejak awal sebelum berkembang menjadi krisis. Contohnya, jika tiba-tiba banyak pelanggan melaporkan kegagalan transaksi, sistem akan menandai hal ini sebagai anomali sehingga tim teknis dapat segera melakukan investigasi.
Manfaat Pentingnya bagi Bisnis
Penerapan unsupervised learning dalam customer support membawa dampak yang baik untuk bisnis. Dengan menganalisis percakapan pelanggan secara real-time, perusahaan dapat meningkatkan efisiensi sekaligus memberikan pengalaman layanan yang lebih cepat, personal, dan efektif.
1. Proactive Issue Detection
Dengan menganalisis percakapan pelanggan secara real-time, perusahaan dapat menemukan bug atau gangguan layanan yang sedang muncul. Deteksi proaktif ini membantu tim teknis memperbaiki masalah sebelum meluas, sehingga meminimalkan dampak terhadap pelanggan.
2. Smarter Self-Service
Analisis terhadap pencarian pelanggan yang gagal menemukan jawaban dapat mengungkap celah dalam basis pengetahuan perusahaan. Dari sini, tim support bisa memperbaiki artikel FAQ atau menambah dokumentasi baru sehingga pelanggan bisa menyelesaikan masalah mereka sendiri tanpa perlu menghubungi agent.
3. Automated Ticket Triaging
Ribuan tiket dukungan yang masuk setiap hari dapat dikelompokkan secara otomatis berdasarkan kesamaan isu. Hal ini mempercepat proses penanganan karena tiket bisa langsung dialokasikan ke tim yang relevan tanpa penyortiran manual.
4. Faster AI Development
Data percakapan mentah sering kali tidak terstruktur, sehingga membutuhkan waktu lama untuk dilatih ke dalam model AI. Dengan unsupervised learning, data dapat diorganisir secara otomatis, sehingga proses pengembangan dan pelatihan model AI menjadi lebih cepat dan efisien.
Tools dan Teknik
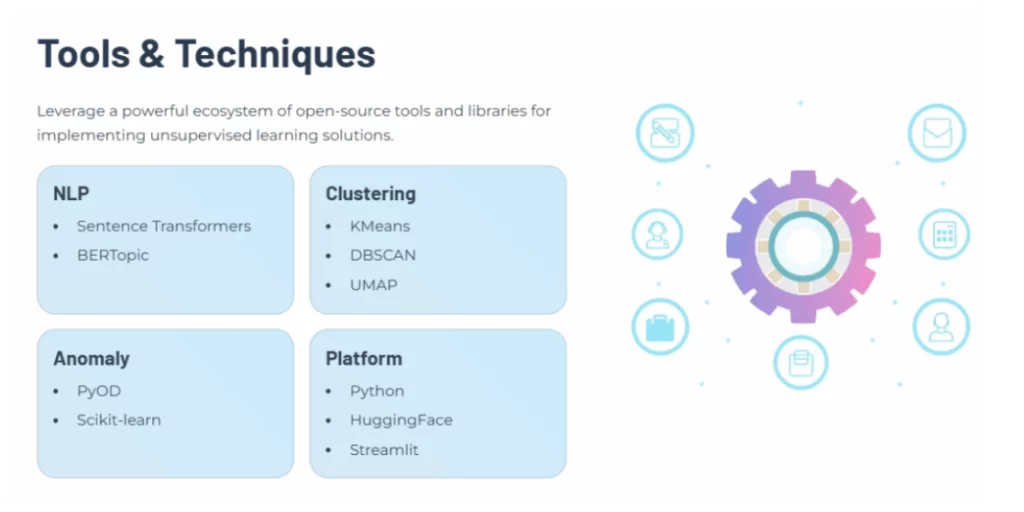
Untuk mengimplementasikan solusi unsupervised learning dalam customer support, ekosistem open-source menyediakan berbagai macam tools dan library yang sangat powerful. Dengan kombinasi yang tepat, perusahaan bisa membangun pipeline analitik dari tahap preprocessing, embedding, hingga visualisasi insight.
1. Natural Language Processing (NLP)
Setelah teks pelanggan diolah dengan NLP untuk memahami konteks dan tema percakapan, langkah selanjutnya adalah mengelompokkan data tersebut dengan teknik dan tools sebagai berikut:
- Sentence Transformers: Digunakan untuk menghasilkan representasi vektor dari teks percakapan pelanggan, sehingga memudahkan analisis semantik.
- BERTopic: Library populer untuk melakukan topic modeling berbasis transformer yang lebih akurat dalam mengidentifikasi tema percakapan.
2. Clustering Algorithms
Setelah data dikelompokkan dengan clustering, langkah berikutnya adalah memastikan kualitas hasil analisis, melalui tools dan teknik sebagai berikut:
- K-Means: Algoritma klasik untuk mengelompokkan data ke dalam cluster berdasarkan kemiripan.
- DBSCAN: Cocok untuk mendeteksi cluster dengan bentuk tidak beraturan serta mengidentifikasi noise/outlier.
- UMAP: Digunakan untuk dimensionality reduction, memudahkan visualisasi data berdimensi tinggi dalam bentuk 2D atau 3D.
3. Anomaly Detection
Anomaly Detection berfokus pada identifikasi pola atau data yang menyimpang dari mayoritas, dengan detail tools dan teknik sebagai berikut:
- PyOD (Python Outlier Detection): Framework khusus untuk mendeteksi outlier dan anomali pada data besar.
- Scikit-learn: Menyediakan berbagai algoritma machine learning termasuk metode anomaly detection seperti Isolation Forest dan One-Class SVM.
4. Platform & Deployment
Dengan memanfaatkan kombinasi tools di atas, perusahaan bisa membangun solusi unsupervised learning yang lengkap, mulai dari ekstraksi data, pembentukan embedding, clustering, anomaly detection, hingga penyajian insight dalam dashboard yang mudah dipahami.
- Python: Bahasa pemrograman utama untuk eksperimen dan implementasi machine learning.
- HuggingFace: Ekosistem model pre-trained yang mendukung NLP modern, termasuk embedding untuk clustering dan topic modeling.
- Streamlit: Framework ringan untuk membangun dashboard interaktif yang memvisualisasikan hasil analisis secara real-time.
Unsupervised Learning untuk Customer Support yang Cerdas
Dengan kemampuan mengelompokkan topik, mendeteksi anomali, hingga melakukan segmentasi pelanggan, teknologi ini membantu perusahaan merespons lebih cepat sekaligus membangun layanan yang lebih personal.
Di tengah ledakan data interaksi digital, pendekatan ini bukan hanya meningkatkan efisiensi tim support, tetapi juga membuka jalan menuju pengalaman pelanggan yang lebih cerdas dan proaktif.
Siap mengubah percakapan pelanggan menjadi kecerdasan real-time? Mulailah perjalanan Anda bersama Qiscus dan temukan bagaimana unsupervised learning dapat menghadirkan layanan pelanggan yang lebih cepat, personal, dan efisien!


